728x90
반응형
PART 1: 빅데이터 분석 기획
Chapter 01: 빅데이터의 이해
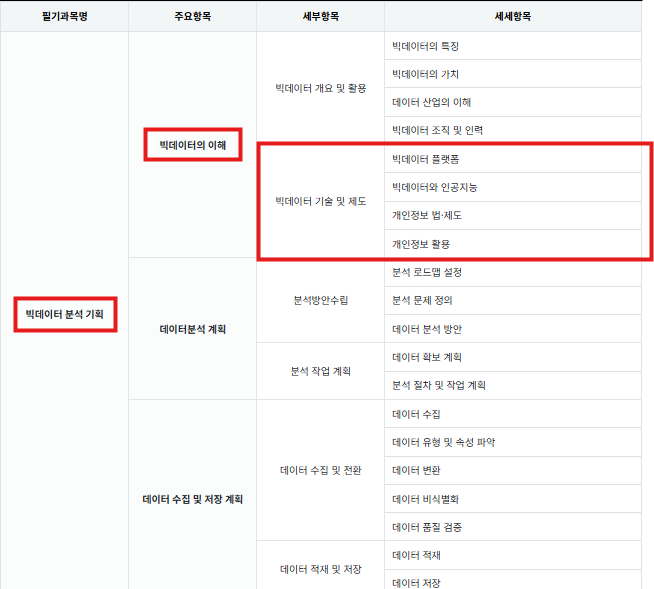
SECTION 02: 빅데이터 기술 및 제도
✅ 01 빅데이터 플랫폼
빅데이터 플랫폼은 빅데이터를 수집, 저장, 관리, 분석하는 기술적 환경입니다.
- 대표적으로 하둡(Hadoop), 스파크(Spark), 그리고 클라우드 기반 플랫폼(AWS, Azure, GCP)이 활용됩니다.
핵심 플랫폼의 특징
- 하둡(Hadoop)
- HDFS(분산파일 시스템), MapReduce(배치 처리), YARN(자원 관리), Hive(SQL 기반 분석)
- 주로 대량 데이터의 배치 처리에 사용됨
- 스파크(Spark)
- 인메모리(In-memory) 처리를 통해 빠른 성능 제공
- 배치 처리와 실시간 스트리밍 분석, 머신러닝 가능
- 클라우드 플랫폼
- AWS EMR, Azure Databricks, GCP BigQuery 등의 서비스로 빠른 확장성과 유연성 제공
✅ 시험 출제 포인트
- 하둡과 스파크의 주요 특징과 차이점
- 클라우드 플랫폼의 특성 및 대표적인 서비스 이해
✅ 02 빅데이터 처리 기술
2.1. 빅데이터 처리과정
데이터 생성 > 데이터 수집 > 저장(공유) > 처리 > 분석 > 시각화
2.2. 빅데이터 처리 기술 구분
빅데이터 처리 기술은 크게 배치 처리와 실시간 처리로 구분됩니다.
- 배치 처리(Batch Processing)
- 대표 기술: Hadoop MapReduce
- 주기적으로 모은 데이터를 일괄적으로 처리하는 방식
- 실시간 처리(Real-Time Processing)
- 대표 기술: Apache Kafka, Apache Flink, Spark Streaming
- 데이터를 즉시 처리하여 즉각적인 반응 및 의사결정 지원
✅ 시험 출제 포인트
- 배치 처리와 실시간 처리의 개념 및 차이점
- 실시간 처리 기술의 실제 산업 적용 사례 이해
2.3. 빅데이터 수집
- 크롤링
- 로그 수집기
- 센서 네트워크
- RSS Rader/ API
- ETL 프로세스: 다양한 원천 데이터를 취합해 추출하고 공통된 형식으로변환하여 적재하는 과정
2.4. 빅데이터 저장
✅ HDFS (Hadoop Distributed File System)
- 대용량 파일을 분산 환경에서 저장하는 기술
- 데이터 복제를 통한 내결함성(Fault-tolerance) 보장
- 읽기 중심의 빠른 데이터 접근 가능
- 대규모 데이터 배치 처리(MapReduce)에 최적화
✅ NoSQL (비관계형 데이터베이스)
- 스키마가 없거나 유연한 데이터 저장 가능
- 수평적 확장(Scale-out)이 가능하여 대용량 데이터 저장 및 실시간 처리에 적합
- 대표적인 유형: Key-Value(Redis), Document(MongoDB), Columnar(HBase), Graph(Neo4j)
✅ 클라우드 스토리지 (Cloud Storage)
- 인터넷 기반으로 데이터를 저장하는 기술
- 높은 확장성과 유연성으로 용량을 쉽게 조절 가능
- 대표적인 서비스: Amazon S3(대용량 오브젝트 저장), Azure Blob Storage(비정형 데이터 저장), Google Cloud Storage(대규모 데이터 저장 및 관리)
✅ 분산파일 시스템
- 네트워크로 공유하는 여러 호스트의 파일에 접근할 수 있는 파일 시스템
- 데이터를 분산하여 저장하면 데이터 추출 및 가공 시 빠르게 처리할 수 있다.
- HDFS, 아마존 S3
2.5. 빅데이터 처리 분산시스템과 병렬 시스템
- 분산 시스템(Distributed System)
- 여러 대의 컴퓨터가 네트워크로 연결되어 데이터를 나누어 처리하는 구조
- 시스템 장애가 발생해도 전체 서비스는 유지될 수 있는 내결함성(Fault-tolerance) 제공
- 대표 기술: Hadoop, Apache Spark, Apache Flink
- 수평적 확장(Scale-out)이 가능해 데이터 증가에 효율적 대응 가능
- 병렬 시스템(Parallel System)
- 하나의 작업을 여러 프로세서나 코어가 동시에 처리하여 성능을 높이는 시스템
- CPU나 GPU의 다중 코어 활용하여 작업 속도를 극대화
2.6. 빅데이터 분석
📌 데이터 분석 방법의 분류
- 탐구 요인 분석(Exploratory Factor Analysis, EFA)
- 자료의 구조가 명확하지 않을 때 사용
- 잠재된 요인을 발견하기 위한 분석 방법
- 변수들 간의 상관관계를 통해 공통요인을 도출
- 확인 요인 분석(Confirmatory Factor Analysis, CFA)
- 기존의 이론이나 가설을 검증하기 위한 분석 방법
- 미리 정해진 요인을 데이터가 얼마나 잘 설명하는지 확인
- 가설의 타당성을 통계적으로 입증하기 위해 사용
📌 빅데이터 분석방법의 종류와 특성
- 분류(Classification)
- 데이터를 미리 정의된 범주로 나누는 기법
- 지도학습 알고리즘 활용 (의사결정나무, 로지스틱 회귀 등)
- 군집화(Clustering)
- 비슷한 특성을 가진 데이터를 군집으로 묶는 방법
- 비지도학습 기법 (K-means, 계층적 군집화 등)
- 기계학습(Machine Learning)
- 데이터를 통해 패턴을 학습하고 예측모델 구축
- 지도학습, 비지도학습, 강화학습을 모두 포함
- 텍스트 마이닝(Text Mining)
- 자연어 처리(NLP)를 통해 텍스트 데이터에서 패턴을 발견하는 분석기법
- 키워드 추출, 주제 분석(Topic Modeling) 등 활용
- 웹 마이닝(Web Mining)
- 웹 데이터에서 사용자의 행동이나 패턴 분석
- 웹 사용 마이닝(로그 분석), 웹 내용 마이닝(콘텐츠 분석), 웹 구조 마이닝(링크 분석)으로 구분
- 오피니언 마이닝(Opinion Mining)
- 고객의 의견, 리뷰 등에서 특정 주제에 대한 견해를 분석하는 기법
- 제품 리뷰, 서비스 평가 등의 분야에서 활용
- 리얼리티 마이닝(Reality Mining)
- 센서 데이터를 통해 개인의 행동 패턴을 분석하는 방법
- 위치 정보, 모바일 사용 데이터 등을 활용하여 사회적 상호작용 분석
- 소셜 네트워크 분석(Social Network Analysis, SNA)
- 네트워크의 연결 관계와 구조를 분석하는 기법
- 영향력 분석, 중심성 분석 등으로 사회적 관계 및 정보 흐름을 파악
- 감성 분석(Sentiment Analysis)
- 텍스트 데이터에서 감정이나 정서(긍정, 부정, 중립)를 분석하는 기법
- 소셜미디어 모니터링, 마케팅 성과 측정 등에 활용
✅ 03 빅데이터와 인공지능(AI)
📌 머신러닝(Machine Learning, ML)의 유형과 특징
머신러닝은 크게 지도학습, 비지도학습, 강화학습으로 나눌 수 있습니다.
- 지도학습(Supervised Learning)
- 레이블(Label)이 지정된 데이터를 통해 학습
- 주요기법:
- 분류(Classification): 로지스틱 회귀, 의사결정나무, 서포트벡터머신(SVM)
- 회귀(Regression): 선형회귀, 다중회귀, 리지·라쏘 회귀 등
- 비지도학습(Unsupervised Learning)
- 레이블 없이 데이터의 특성이나 패턴을 분석하는 기법
- 주요기법:
- 군집화(Clustering): K-means, 계층적 군집화
- 차원 축소(Dimensionality Reduction): 주성분분석(PCA), t-SNE 등
- 이상탐지(Anomaly Detection)
- 준지도학습(Semi-supervised Learning)
- 일부 데이터만 레이블이 있고, 대부분 데이터는 레이블이 없는 경우 활용
- 소량의 레이블 데이터와 다량의 비레이블 데이터를 결합하여 정확성 향상
- 대표 사례: 웹 문서 분류, 이미지 인식 (소량의 레이블링으로 전체 데이터 분류 성능 개선)
- 강화학습(Reinforcement Learning)
- 시행착오를 통해 최적의 행동을 학습
- 보상(Reward)과 처벌(Penalty)을 통해 최적화된 행동을 결정
- 주요 사례: 게임 AI, 자율주행차, 로봇 제어 등
📌 딥러닝(Deep Learning)의 주요 알고리즘과 특성
딥러닝은 인공신경망 기반으로 인간 뇌의 구조를 모방한 기술로, 주로 대용량 데이터 분석과 복잡한 패턴 학습에 사용됩니다.
- 인공신경망(Artificial Neural Networks, ANN)
- 인간의 뉴런 구조를 모방하여 입력값을 통해 패턴을 학습
- 예측, 분류 및 회귀 분석 등 다양한 분야에서 사용
- 컨볼루션 신경망(Convolutional Neural Networks, CNN)
- 이미지 분석에 특화된 딥러닝 구조
- 이미지 인식, 객체 탐지, 영상 처리 등에서 탁월한 성능을 보임
- 순환 신경망(Recurrent Neural Networks, RNN)
- 시계열 데이터와 같은 연속적인 데이터 처리에 적합
- 자연어 처리(NLP), 텍스트 분석, 음성 인식 등에서 많이 활용
✅ 시험 출제 포인트
- 머신러닝과 딥러닝 기법의 주요 차이점
- 지도학습, 비지도학습, 준지도학습, 강화학습은 머신러닝! 나머지는 딥러닝
📌 추가적으로 알아야 할 AI 분석기법
✅ GAN (Generative Adversarial Network, 생성적 적대 신경망)
- 생성자(Generator)와 판별자(Discriminator)의 두 신경망이 상호 경쟁하며 학습하는 모델
- 생성자는 실제 데이터와 비슷한 데이터를 생성하고, 판별자는 생성된 데이터의 진위를 판별하는 방식으로 경쟁
- 주요 활용 분야:
- 이미지 생성 및 변형
- 데이터 증강(Data Augmentation)
- 가짜 데이터 생성 및 딥페이크(DeepFake) 등
✅ 앙상블 학습 (Ensemble Learning) 🌟
- 여러 개의 모델을 결합하여 예측 정확도와 안정성을 높이는 방법
- 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)으로 구분 가능
- 배깅(Bagging)
- 대표기법: 랜덤 포레스트(Random Forest)
- 여러 개의 모델을 병렬적으로 학습하여 다수결로 예측 결과 도출
- 부스팅(Boosting)
- 약한 모델을 순차적으로 학습하여 성능을 점진적으로 개선
- 대표 알고리즘: AdaBoost, Gradient Boosting, XGBoost, LightGBM
- 스태킹(Stacking)
- 여러 모델의 예측 결과를 다시 모델링하여 최종 결과 예측
- 고도의 정확성 확보 가능
- 배깅(Bagging)
✅ 04 개인정보 개요
개인정보는 특정 개인을 식별할 수 있는 모든 정보입니다.
- 개인정보 유형
- 일반 개인정보 (이름, 주소 등)
- 민감정보 (건강정보, 정치 성향 등)
- 고유식별정보 (주민등록번호 등)
✅ 시험 출제 포인트
- 개인정보의 유형별 특징과 중요성
- 개인정보 침해 사례 및 보호 방법 이해
✅ 05 개인정보 법 제도
국내외 주요 개인정보 보호 법제도를 명확히 이해하는 것이 중요합니다.
- 국내법
- 개인정보 보호법, 정보통신망법, 신용정보법
- 국제법
- GDPR(유럽 개인정보 보호 규정)
✅ 시험 출제 포인트
- 국내법 3가지 (개인정보 보호법, 정보통신망법, 신용정보법)
✅ 06 개인정보 비식별화
개인정보 비식별화는 개인을 특정할 수 없도록 정보를 처리하는 기술입니다.
📌 개인정보 비식별화의 단계별 절차
개인정보 비식별화는 다음과 같은 체계적인 단계로 진행됩니다.
① 사전 검토
- 비식별화할 데이터의 특성, 목적, 범위를 명확히 정의
- 개인정보 비식별화 필요성 검토
② 사전 준비
- 비식별화 대상 데이터 선정
- 데이터 처리 환경 구축(도구, 소프트웨어 등)
③ 비식별 조치 (기법 적용)
- 가명화, 총계처리(집계), 데이터 마스킹, 데이터 범주화, 잡음 추가 등 비식별화 기법 적용
④ 적정성 평가
- 재식별 위험 평가 (k-익명성, l-다양성, t-근접성 등 활용)
- 비식별화 조치 결과 평가 및 적정성 검증
④ 사후 관리 (Post-management)
- 재식별 가능성 주기적 점검 및 평가
- 비식별화 데이터 관리 체계 수립 및 운영
- 비식별화 데이터 활용 목적 외 사용 금지 등 관리 방안 마련
- 재식별 금지‼️
6.1. 비식별화 기법
① 가명화(Pseudonymization)
- 데이터를 처리하여 추가 정보 없이는 개인을 특정할 수 없도록 함
- 추가 정보가 있을 경우 다시 개인을 식별할 수 있으므로, 관리적 보안 조치가 필요
- 예시: 이름을 임의의 코드나 번호로 변경
② 총계처리(Aggregation, 집계)
- 개별 데이터를 일정 기준에 따라 집계하여 개인 식별성을 제거하는 방법
- 주로 통계 데이터 생성에 사용
- 예시: 연령대별, 지역별 평균 소득 데이터
③ 데이터 마스킹(Data Masking)
- 중요 개인정보를 별도의 문자 또는 기호로 변환하여 가리는 방법
- 주로 테스트 DB, 개발 환경 등에서 개인정보 노출을 방지하기 위해 사용
- 예시: 주민번호 뒷자리 *** 처리, 전화번호 일부 마스킹 처리
④ 데이터 범주화(Data Generalization)
- 데이터 값을 좀 더 일반적인 범주로 변환하여 세부 정보를 숨기는 방식
- 예시: 정확한 생년월일 대신 나이대(20대, 30대)로 처리
⑤ 잡음 추가(Noise Addition)
- 원본 데이터에 의도적으로 임의의 값을 추가하여 개인 식별성을 낮추는 방식
- 예시: 위치 정보에 약간의 무작위 오차값을 추가하여 정확한 위치를 숨김
✅ 대표적인 재식별 위험 평가 방법
- k-익명성(k-Anonymity)
- 최소한 동일한 특성을 가진 데이터가 K개 이상 존재해야 함
- 동일한 속성을 가진 데이터 그룹 내 개인 식별 방지
- l-다양성(l-diversity, l-근접성) 🌟
- k-익명성의 한계 극복을 위한 기법
- 민감 정보의 다양성을 보장함으로써 개인정보 보호
- 특정 민감 정보가 편중되지 않도록 최소 L개 이상의 다양한 값을 보유하게끔 처리하는 기법
- t-근접성(t-Closeness)
- k-익명성과 l-다양성을 더욱 강화한 방식
- 민감 정보의 분포가 전체 데이터 분포와 유사하게 유지되어야 함
✅ 시험 출제 포인트
- 다양한 비식별화 기법과 사례 숙지
- 재식별 위험 평가 방법과 관리 방안 이해
✅ 07 가명정보
가명정보는 개인정보를 가공하여 개인을 직접적으로 식별하지 못하게 한 정보입니다.

✅ 시험 출제 포인트
- 개인정보, 가명정보, 익명정보 차이점 구분
✅ 08 개인정보 활용
| 분류 | 위기 요인 | 통제방한 |
| 데이터 수집 | 사생활 침해로 위기 발생 | 동의에서 책임으로 강화하여 통제 |
| 데이터 활용 | 책임 원칙 훼손으로 위기 발생 | 결과 기반 책임 원칙을 고수하여 통제 |
| 데이터 처리 | 데이터 오용 | 알고리즘 접근을 허융하여 통제 |
✅ 시험 출제 포인트
- 위기 요인 종류 3가지 암기
💡 도움이 되셨다면 댓글과 공감 부탁드립니다! 😊
📌 더 많은 빅데이터 분석기사 자료와 프로그래밍 자료는 블로그에서 확인하세요!
✉️ 문의나 피드백은 댓글이나 이메일로 남겨주세요!
728x90
반응형
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [P01CH03S01] 데이터 수집 및 전환 (0) | 2025.03.12 |
|---|---|
| [P01CH02S01] 분석 방안 수립 (1) | 2025.03.11 |
| [P01CH01S01] 데이터와 정보 (0) | 2025.03.10 |
| PART 1: 빅데이터 분석 기획 (0) | 2025.03.10 |
| PART 0: 2025년 빅데이터분석기사 독학 (feat. 시험 일정 및 개요, 이기적 교재) (0) | 2025.03.10 |



