PART04: 빅데이터 결과해석
CHAPTER01: 분석모형 평가 및 개선

[P04CH01S01-S02] 분석모형 평가 및 개선
1. 평가 지표
1.1 지도학습-분류모델 평가 지표
(1) 오차 행렬
: 훈련을 통한 예측 성능을 측정하기 위해 예측 값과 실제값을 비교하기 위한 표이다

오차 행렬은 크게 4가지로 나누어 볼수 있는데 간단히 설명하면 다음과 같다.
- TN(True Negative) : 예측을 Negative로 하였고 그 결과도 Negative인 경우
- TP(True Positive) : 예측을 Positive로 하였고 그 결과도 Positive인 경우
- FN(True Negative) : 예측을 Negative로 하였으나 결과는 Positive인 경우
- FP(True Positive) : 예측을 Positive로 하였으나 결과는 Negative인 경우
(1) 정확도 (Accuracy)
- 전체 샘플 중에서 모델이 올바르게 예측한 비율
- 계산식: (TP + TN) / (TP + TN + FP + FN)
- 단점: 클래스 불균형이 심할 경우 왜곡될 수 있음
(2) 정밀도 (Precision)
- 모델이 양성으로 예측한 샘플 중 실제 양성일 확률
- 계산식: TP / (TP + FP)
- 잘못된 양성 예측을 줄이는 것이 중요할 때 사용
(3) 재현율 (Recall, Sensitivity)
- 실제 양성 샘플 중에서 모델이 양성으로 정확하게 예측한 비율
- 계산식: TP / (TP + FN)
- 잘못된 음성 예측을 줄이는 것이 중요할 때 사용
(4) F1 Score
- 정밀도와 재현율의 조화 평균
- 계산식: 2 × (Precision × Recall) / (Precision + Recall)
- 정밀도와 재현율 간 균형이 중요할 때 사용
(5) ROC(Receiver Operating Characteristic) 곡선
- FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변화하는지를 나타내는 곡선
- FPR = FP / (FP + TN) (실제 False 중에서 False로 예측한 비율)
- TPR = TP / (TP + FN) (실제 True 중에서 True로 예측한 비율 = Recall)

(6) AUC (Area Under the Curve)
- ROC 곡선 아래의 면적으로 모델의 전체적인 성능을 평가하는 지표
- AUC 값이 1에 가까울수록 좋은 모델, 0.5에 가까울수록 무작위 예측과 동일
1.2 지도학습-회귀모델 평가 지표
(1) SSE(Sum Squared Error): 실제값과 예측값의 차이를 제곱하여 더한 값
(2) MSE(Mean Squared Error): 실제값과 예측값의 차이의 제곱에 대한 평균을 취한 값(평균제곱 오차)
(3) RMSE: MSE에 루트를 취한 값
(4) MAE(Mean Absolute Error): 실제값과 예측값의 차이의 절대값을 합한 평균값
(5) 결정계수 R²: 회귀모형이 실제값에 얼마나 잘 적합하는지에 대한 비율
(6) Adjusted R²: 다변량 회귀분석에서 독립변수가 많아질수록 결정계수가 높아지는 것을 보완
1.3 비지도학습-군집분석 평가지표
- 실측자료에 라벨링이 없으므로 모델에 대한 성능평가가 어렵다.
- 실루엣 계수: 군집에 속한 요소들 간 거리들의 평균, 실루엣 지표가 0.5보다 크면 적절한 군집모델
- Dunn Index: 군집 간 거리의 최소값을 분자, 군집 내 요소 간 거리의 최대값을 분모로 하는 지표, Dunn Index값이 클수록 좋음
[머신러닝] 클러스터링 평가지표 - 실루엣 계수 (1)
실루엣 계수(Silhouette Coefficient) : 각 데이터 포인트와 주위 데이터 포인트들과의 거리 계산을 통해 값을 구하며, 군집 안에 있는 데이터들은 잘 모여있는지, 군집끼리는 서로 잘 구분되는지 클러
studying-haeung.tistory.com
2. 분석모형 진단
2.1 정규성 가정
- 데이터가 정규분포를 따르는지를 검정
- (1) 중심극한정리: 동일한 확률분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규분포에 가까워진다는 이론
- (2) 정규성 검정 종류
- 샤피로-윌크 검정: 표본수 2천 개 미만에 적합
- 콜모고로프-스미르노프 검정: 표본수 2천 개 초과인 경우 적합
- Q-Q 플롯: 데이터 셋이 정규분포를 따르는지 판단하는 시각적 분석 방법, 표본수(n)가 소규모일 경우 적합
2.2 잔차 진단
- 잔차의 합은 0이며, 특정 패턴을 가지지 않음
- (1) 잔차의 정규성 진단: Q-Q Plot 등 시각화 도표를 이용하여 잔차의 정규분포 여부를 확인
- (2) 잔차의 등분산성 진단
- (3) 잔차의 독립성 진단: 자기 상관 여부를 판단하여 시계열 분석이 필요할 경우 회귀분석을 진행
3. k-폴드 교차검증
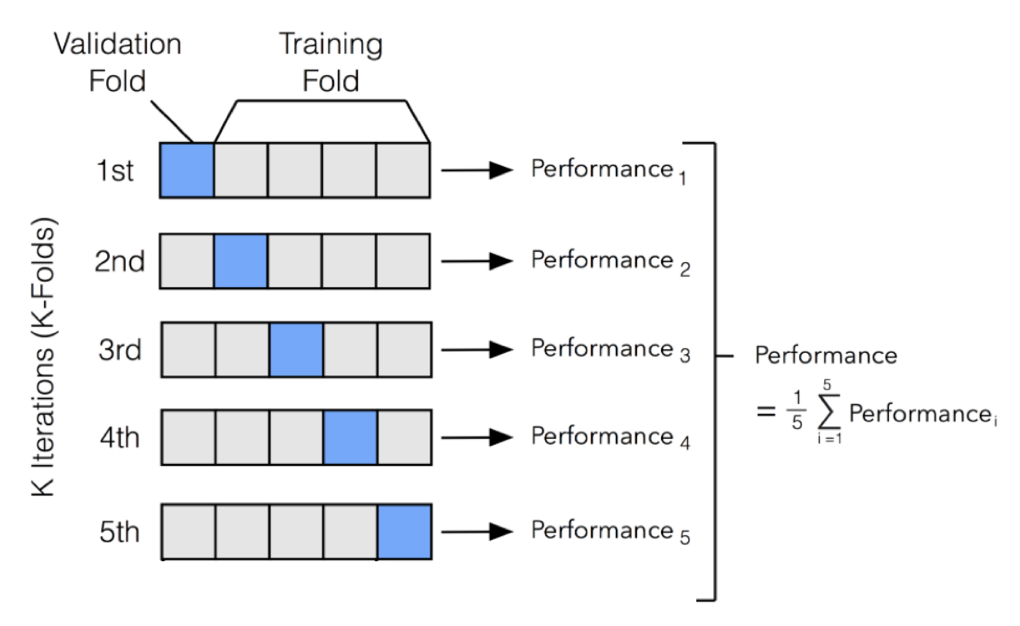
- 과적합 방지를 위한 기법
- 전체 데이터 셋을 k개의 서브셋으로 분리하여 그중 k-1개를 훈련데이터로 사용하고 1개의 서브셋을 테스트데이터로 사용하여 모델 성능을 평가
- 홀드아웃 기법: 데이터를 학습/검증/테스트 데이터로 나누는 방식, 데이터 크기에 따라 성능 추정에 영향
4. 적합도 검정
- 데이터가 가정된 확률에 적합하게 따르는지 검정
- T검정은 범주형 변수 분석에 해당되지 않음
- (1) 카이제곱 검정: 기대값과 관측값을 이용하여 k개의 범주별 관측치들과 가정된 분포의 적합도를 검정
- (2) 콜모고로프-스미르노프 검정: 관측된 표본분포와 가정된 분포 사이의 적합도를 검사하는 검정법, 연속형 데이터에도 적용 가능
2. 분석모형 개선
2.1 과대적합 방지
- 정규화, 드롭아웃 등을 활용하여 적절한 복잡도를 가진 모델을 자동으로 탐색한다.
- 드롭아웃: 신경망 모델에서 은닉층의 뉴런을 임의로 삭제하면서 학습하는 방법 (학습 시간이 오래 걸릴 수 있음)
- 가중치 감소: 학습과정에서 큰 가중치에 대해서는 큰 페널티를 부과하여 가중치의 절대값을 가능한 작게 만든다.
- L2 규제 (릿지 회귀): 가중치 제곱의 합을 추가하여 큰 가중치를 제한 (λ 값이 클수록 강한 규제)
- L1 규제 (라쏘 회귀): 가중치의 절대값 합을 추가하여 일부 가중치를 0으로 만듦 (특성 선택 효과)
- 편향-분산 트레이드오프: 과대적합과 과소적합 사이의 균형을 찾는 과정
2.2 매개변수 최적화
옵티마이저라고 많이 하죠.
자세한 내용은 하단 블로그를 참조 하면 좋을 것 같습니다.
딥러닝에 대해 따로 정리 할 일 있을 때 저 스스로 정리해보려구요
https://amber-chaeeunk.tistory.com/23
딥러닝) optimizer ( SGD , Momentum , AdaGrad , RMSProp, Adam )
1. Stochastic Gradient Descent (SGD) SGD는 현재 위치에서 기울어진 방향이 전체적인 최솟값과 다른 방향을 가리키므로 지그재그 모양으로 탐색해나간다. 즉, SGD의 단점은 비등방성(anisotropy)함수에서는
amber-chaeeunk.tistory.com
- 확률적 경사 하강법(SGD): 손실함수의 기울기를 이용하여 최적의 매개변수 값을 찾음
- 모멘텀: 경사 하강 과정에서 관성 효과를 추가하여 최적점 수렴 속도를 높임
- AdaGrad: 학습률을 적응적으로 조정하여 초기에 크게 학습하고 점점 감소시킴
- Adam: 모멘텀과 AdaGrad를 결합한 방법론 (학습률과 모멘텀을 조정 가능)
2.3 분석모형 융합
- 앙상블 학습: 여러 예측 모형을 결합하여 최종 성능을 향상
- 장점: 변동성 감소 및 과적합 방지
- 결합 분석 모형: 두 개 이상의 결과 변수를 동시에 분석하는 기법
2.4 최종 모형 선정
- 회귀모형 평가 지표: SSE, R², MAE, MAPE 등
- 분류모형 평가 지표: 특이도, 정밀도, 재현율, 정확도 등
- 비지도학습 모형 평가 지표:
- 군집분석: 군집 타당성 지표
- 연관분석: 지지도 및 신뢰도를 기반으로 평가
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [P04CH01S02] 분석결과 해석 (0) | 2025.03.19 |
|---|---|
| Part 4: 빅데이터 결과 해석 (0) | 2025.03.18 |
| [P03CH02S02] 고급 분석 기법 (0) | 2025.03.18 |
| [P03CH02S01] ✨분석 기법 (feat. 인공지능, 빅데이터) (1) | 2025.03.17 |
| [P03CH01S01-02] 데이터 탐색 기초 (0) | 2025.03.17 |



