그래프에 대해 기초부터 차근차근 학습해보겠습니다. 그래프는 DFS와 BFS를 이해하는 데 필수적인 자료구조이므로, 기초 개념부터 간단한 구현까지 배우면 이후 탐색 알고리즘도 쉽게 이해할 수 있습니다.

1. 그래프란 무엇인가?
- 정의: 그래프는 **노드(Node, 정점)**와 이들을 연결하는 **간선(Edge)**으로 이루어진 자료구조입니다.
- 응용 분야: 네트워크(인터넷, 사회 연결망), 지리정보 시스템(지도), 경로 탐색(길 찾기), 관계 모델링(데이터 관계) 등.
2. 그래프의 주요 용어
- 정점(Vertex): 그래프를 이루는 점. 보통 숫자나 문자로 표현.
- 간선(Edge): 정점 간의 연결선. 관계를 나타냄.
- 방향성(Directionality):
- 무방향 그래프: 간선에 방향이 없음 (A ↔ B).
- 유방향 그래프: 간선에 방향이 있음 (A → B).
- 가중치(Weight): 간선에 비용이나 거리 등 값이 부여된 그래프.
- 인접(Adjacent): 두 정점이 간선으로 연결되어 있을 때 인접한다고 표현.
3. 그래프 표현 방법
그래프는 컴퓨터에서 인접 행렬 또는 인접 리스트로 표현합니다.
(1) 인접 행렬
- 정점을 2차원 배열로 표현.
- 간선이 있으면 1, 없으면 0으로 표시.
- 예제: 노드: 0, 1, 2
간선: (0 ↔ 1), (1 ↔ 2)
0: [0, 1, 0]
1: [1, 0, 1]
2: [0, 1, 0](2) 인접 리스트
- 각 정점이 연결된 정점의 목록을 저장.
- 메모리 효율적이며, 연결된 정점만 저장.
- 예제:C 코드:
int graph[3][3] = {
{0, 1, 0},
{1, 0, 1},
{0, 1, 0}
};4. 그래프의 간단한 구현
(1) 인접 행렬 구현
#include <stdio.h>
int main() {
int graph[3][3] = {
{0, 1, 0},
{1, 0, 1},
{0, 1, 0}
};
printf("노드 1에 연결된 노드: ");
for (int i = 0; i < 3; i++) {
if (graph[1][i] == 1) {
printf("%d ", i);
}
}
printf("\n");
return 0;
}
출력:
노드 1에 연결된 노드: 0 2
(2) 인접 리스트 구현
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int vertex;
struct Node* next;
} Node;
Node* adjList[3]; // 3개의 정점
void addEdge(int src, int dest) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->vertex = dest;
newNode->next = adjList[src];
adjList[src] = newNode;
}
void printGraph() {
for (int i = 0; i < 3; i++) {
printf("노드 %d에 연결된 노드: ", i);
Node* temp = adjList[i];
while (temp) {
printf("%d ", temp->vertex);
temp = temp->next;
}
printf("\n");
}
}
int main() {
// 그래프 초기화
for (int i = 0; i < 3; i++) {
adjList[i] = NULL;
}
addEdge(0, 1);
addEdge(1, 0);
addEdge(1, 2);
addEdge(2, 1);
printGraph();
return 0;
}
출력:
노드 0에 연결된 노드: 1
노드 1에 연결된 노드: 2 0
노드 2에 연결된 노드: 1
DFS(Depth-Frist Search)
좋습니다! DFS(깊이 우선 탐색)의 기초부터 응용까지 차근차근 학습해보겠습니다.
1. DFS란?
DFS(Depth-First Search)는 그래프를 탐색하는 알고리즘으로, 한 노드에서 시작해 가능한 한 깊이로 내려간 후, 더 이상 탐색할 곳이 없으면 되돌아옵니다.
- 특징:
- 스택(Stack)이나 재귀(Recursion)를 이용하여 구현.
- 그래프의 모든 노드를 탐색.
- 경로 탐색, 순열/조합 생성, 백트래킹 등에 자주 사용.
출처: https://upload.wikimedia.org/wikipedia/commons/7/7f/Depth-First-Search.gif
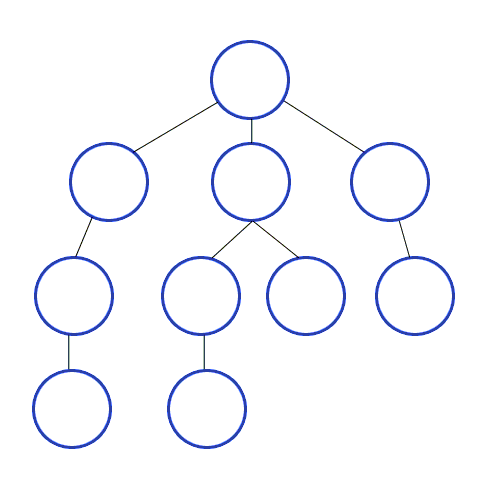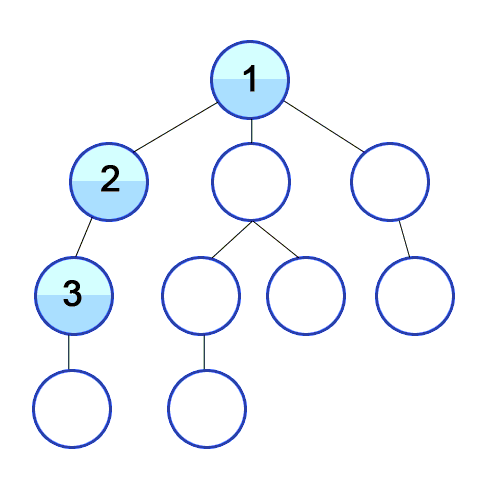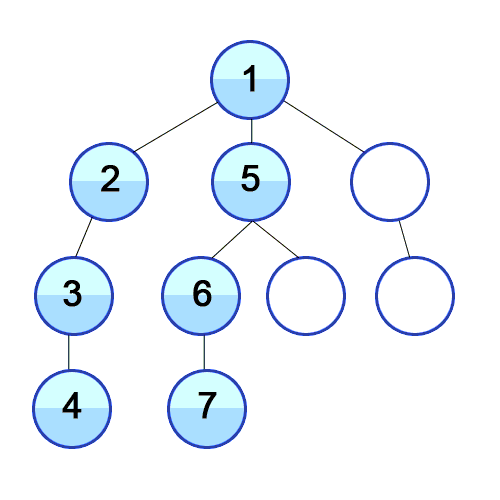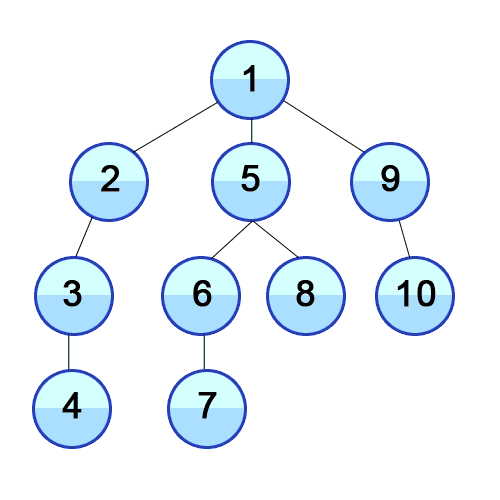
2. DFS 동작 방식
단계
- 시작 노드를 방문.
- 방문한 노드를 기록.
- 방문하지 않은 인접 노드로 이동.
- 더 이상 방문할 노드가 없으면 이전 단계로 되돌아감(백트래킹).
3. DFS 의사 코드
DFS(node):
방문[node] = true
출력(node)
for 연결된 모든 노드 next_node:
if 방문[next_node] == false:
DFS(next_node)
4. DFS 구현 (C 언어)
먼저, DFS를 인접 행렬 방식으로 구현해보겠습니다.
(1) 인접 행렬 기반 DFS + "재귀함수"
#include <stdio.h>
#define MAX 100 // 최대 노드 개수
int graph[MAX][MAX]; // 그래프 (인접 행렬)
int visited[MAX]; // 방문 여부
int n; // 노드의 개수
void DFS(int node) {
printf("%d ", node); // 현재 노드 출력
visited[node] = 1; // 방문 처리
for (int i = 0; i < n; i++) {
if (graph[node][i] == 1 && !visited[i]) {
DFS(i); // 연결된 노드로 이동
}
}
}
int main() {
int edges, u, v;
printf("노드 개수와 간선 개수를 입력하세요: ");
scanf("%d %d", &n, &edges);
for (int i = 0; i < edges; i++) {
printf("간선 (u, v)를 입력하세요: ");
scanf("%d %d", &u, &v);
graph[u][v] = 1; // 간선 추가
graph[v][u] = 1; // 무방향 그래프
}
printf("DFS 탐색 결과: ");
DFS(0); // 0번 노드에서 시작
printf("\n");
return 0;
}
(2) 인접 리스트 기반 DFS - 재귀, 스택(stack)
인접 리스트를 기반으로 스택 기반 DFS 구현과 재귀 기반 DFS 구현을 각각 예시와 함께 보여드리겠습니다.
1. 재귀 기반 DFS 구현
재귀 호출을 사용하여 DFS를 구현합니다. 함수 호출 스택을 이용해 자연스럽게 백트래킹(되돌아가기)을 처리합니다.
코드
#include <stdio.h>
#include <stdlib.h>
#define MAX 100
typedef struct Node {
int vertex; // 연결된 노드 번호
struct Node* next; // 다음 노드를 가리키는 포인터
} Node;
Node* adjList[MAX]; // 그래프의 인접 리스트
int visited[MAX]; // 방문 여부
int n; // 노드의 개수
void addEdge(int src, int dest) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->vertex = dest;
newNode->next = adjList[src];
adjList[src] = newNode;
}
void DFS_Recursive(int currentNode) {
visited[currentNode] = 1;
printf("%d ", currentNode);
Node* temp = adjList[currentNode];
while (temp != NULL) {
int nextVertex = temp->vertex;
if (!visited[nextVertex]) {
DFS_Recursive(nextVertex);
}
temp = temp->next;
}
}
int main() {
int edges, src, dest;
printf("노드 개수와 간선 개수를 입력하세요: ");
scanf("%d %d", &n, &edges);
for (int i = 0; i < edges; i++) {
printf("간선 (출발 노드, 도착 노드)을 입력하세요: ");
scanf("%d %d", &src, &dest);
addEdge(src, dest);
addEdge(dest, src); // 무방향 그래프
}
printf("DFS (재귀) 탐색 결과: ");
DFS_Recursive(0);
printf("\n");
return 0;
}
입출력 예시
입력:
노드 개수와 간선 개수를 입력하세요: 5 4
간선 (출발 노드, 도착 노드)을 입력하세요: 0 1
간선 (출발 노드, 도착 노드)을 입력하세요: 0 2
간선 (출발 노드, 도착 노드)을 입력하세요: 1 3
간선 (출발 노드, 도착 노드)을 입력하세요: 1 4
출력:
DFS (재귀) 탐색 결과: 0 1 3 4 2
2. 스택 기반 DFS 구현 (feat. 동적 배열 할당 malloc )
명시적으로 스택 자료구조를 사용하여 DFS를 구현합니다. 스택에 노드를 저장하고, 스택에서 꺼낸 노드를 탐색하며 백트래킹을 처리합니다.
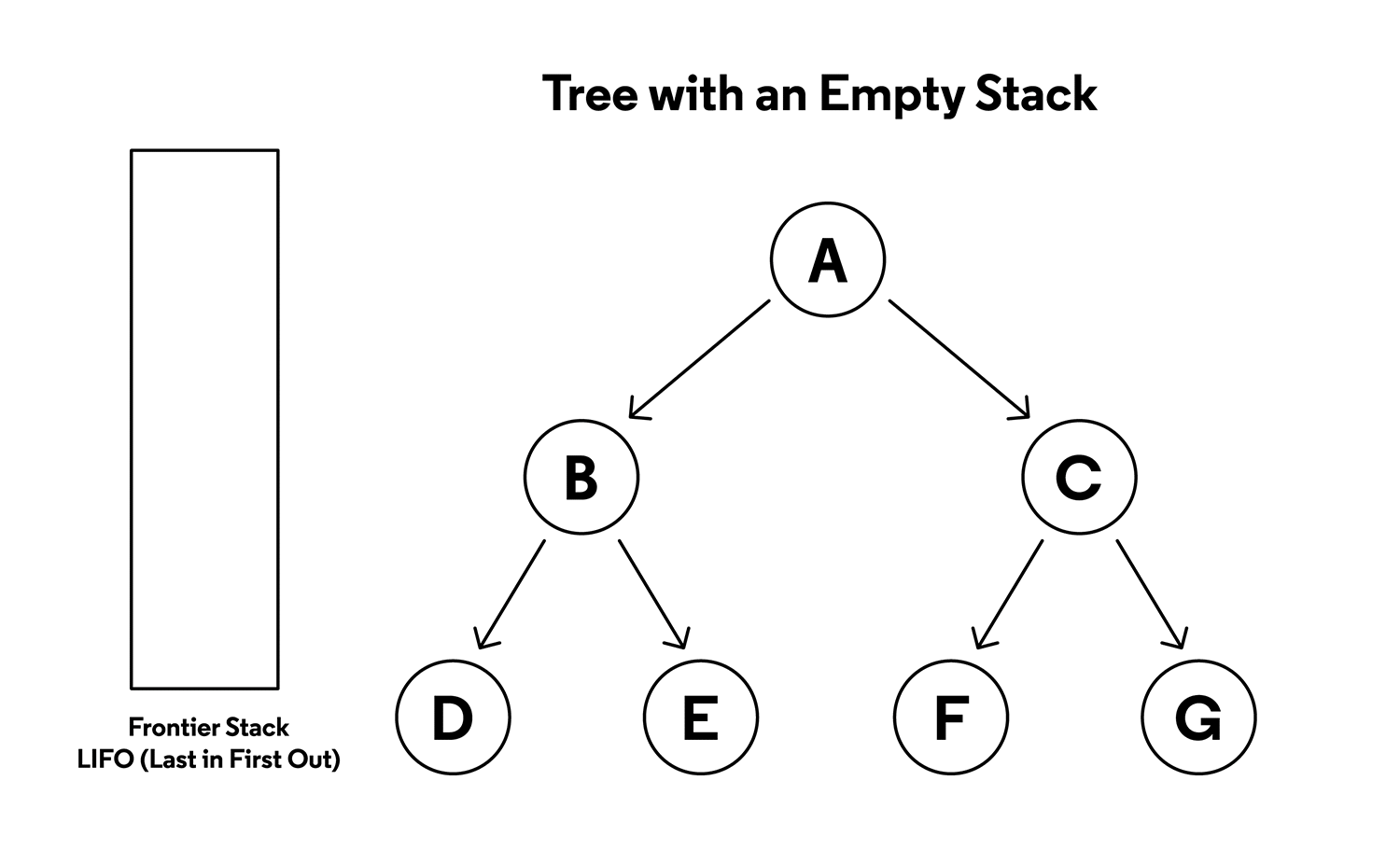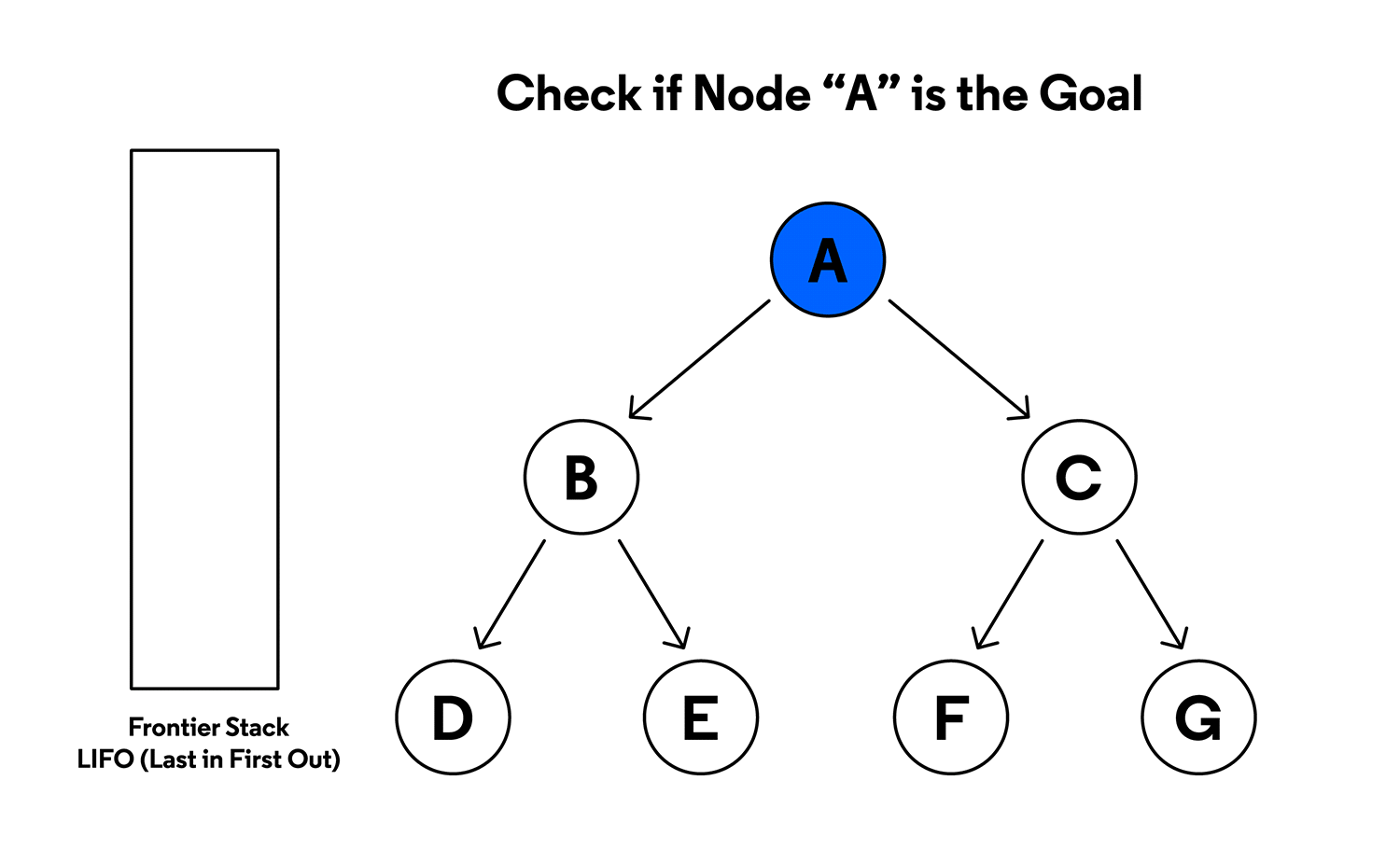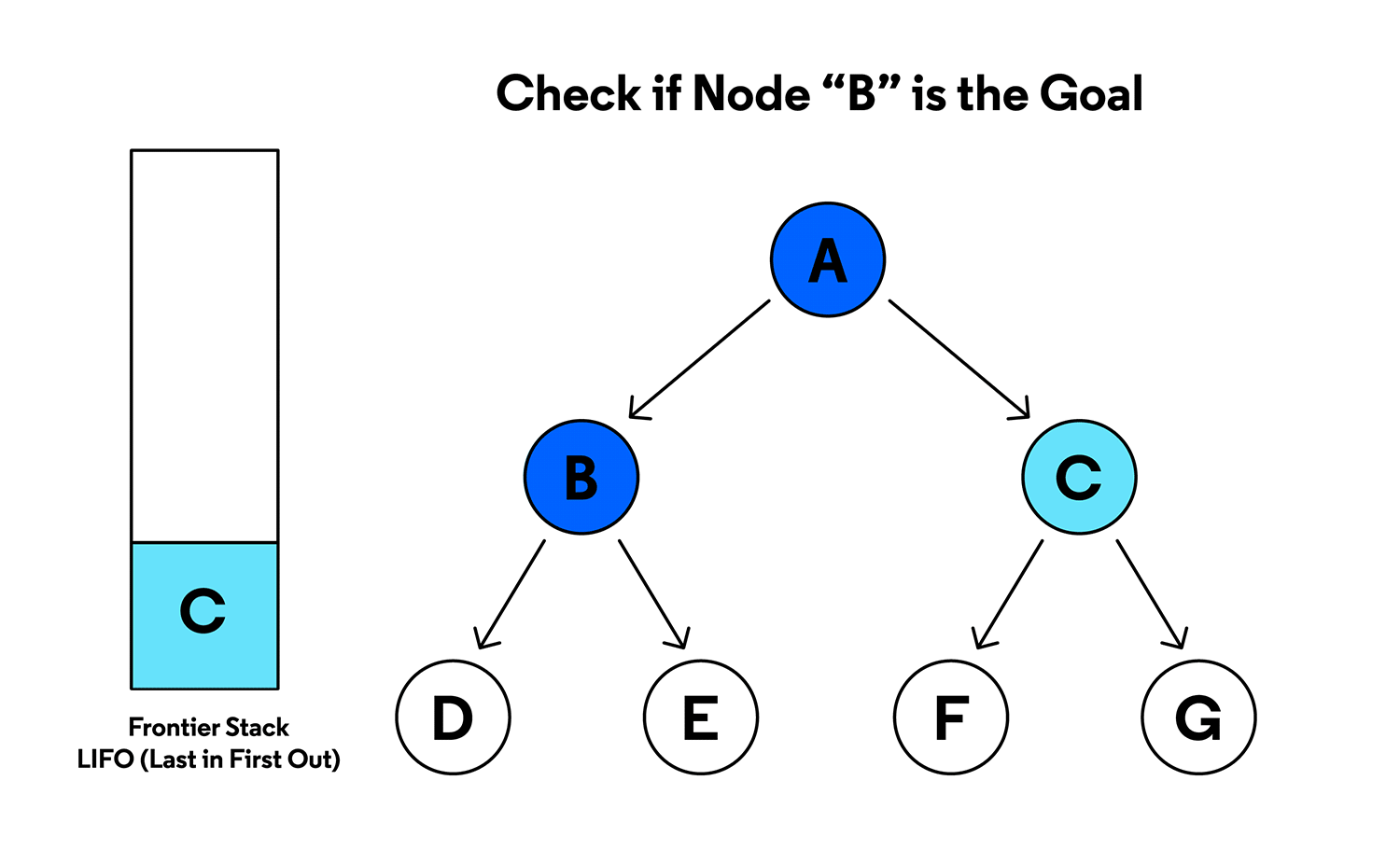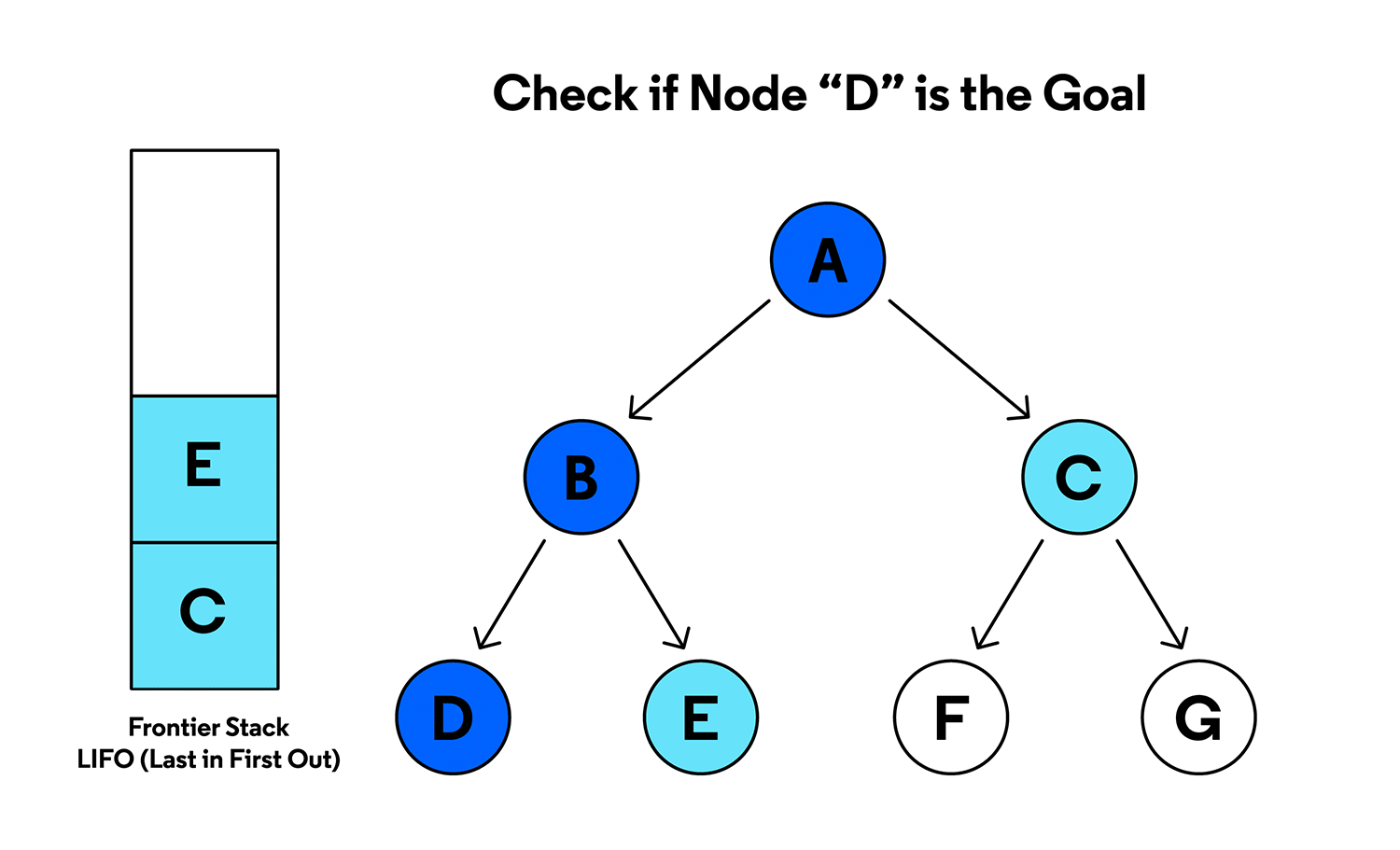
아래는 스택 기반 DFS를 그림에 맞춰 탐색 과정을 단계별로 상세히 설명한 것입니다. LIFO (Last In First Out) 방식을 사용하는 스택을 기준으로 진행됩니다.
그래프 구조
- 시작 노드: AA
- 자식 노드:
- AA → B,CB, C
- BB → D,ED, E
- CC → F,GF, G
1. 초기 상태
- 스택: 빈 상태.
- 탐색 시작: AA.
동작
- AA를 스택에 추가.
- 스택 상태: [A].
2. 스택에서 AA 꺼내고 탐색
- 스택에서 팝: AA.
- 스택 상태: 빈 상태.
- 출력: AA.
- AA의 자식 노드 B,CB, C를 스택에 추가. (이때 CC가 먼저 추가되고 BB가 추가됨.)
스택 상태
- [B, C].
3. 스택에서 BB 꺼내고 탐색
- 스택에서 팝: BB.
- 스택 상태: [C].
- 출력: BB.
- BB의 자식 노드 D,ED, E를 스택에 추가. (이때 EE가 먼저 추가되고 DD가 추가됨.)
스택 상태
- [C, D, E].
4. 스택에서 DD 꺼내고 탐색
- 스택에서 팝: DD.
- 스택 상태: [C, E].
- 출력: DD.
- DD의 자식 노드는 없음 → 아무것도 추가하지 않음.
스택 상태
- [C, E].
5. 스택에서 EE 꺼내고 탐색
- 스택에서 팝: EE.
- 스택 상태: [C].
- 출력: EE.
- EE의 자식 노드는 없음 → 아무것도 추가하지 않음.
스택 상태
- [C].
6. 스택에서 CC 꺼내고 탐색
- 스택에서 팝: CC.
- 스택 상태: 빈 상태.
- 출력: CC.
- CC의 자식 노드 F,GF, G를 스택에 추가. (이때 GG가 먼저 추가되고 FF가 추가됨.)
스택 상태
- [F, G].
7. 스택에서 FF 꺼내고 탐색
- 스택에서 팝: FF.
- 스택 상태: [G].
- 출력: FF.
- FF의 자식 노드는 없음 → 아무것도 추가하지 않음.
스택 상태
- [G].
8. 스택에서 GG 꺼내고 탐색
- 스택에서 팝: GG.
- 스택 상태: 빈 상태.
- 출력: GG.
- GG의 자식 노드는 없음 → 아무것도 추가하지 않음.
스택 상태
- 빈 상태 → 탐색 종료.
출력 순서
- A→B→D→E→C→F→GA → B → D → E → C → F → G.
스택 동작 요약 (단계별 변화)
단계 스택 상태 출력 현재 노드 추가된 노드
| 1 | [A] | AA | - | |
| 2 | [B, C] | AA | B,CB, C | B,CB, C |
| 3 | [C, D, E] | BB | D,ED, E | D,ED, E |
| 4 | [C, E] | DD | −- | - |
| 5 | [C] | EE | −- | - |
| 6 | [F, G] | CC | F,GF, G | F,GF, G |
| 7 | [G] | FF | −- | - |
| 8 | [] | GG | −- | - |
스택 기반 DFS의 특징
- 스택에 푸시하는 순서에 따라 탐색 순서가 달라질 수 있습니다.
- 자식 노드를 추가할 때의 순서(예: C가 먼저 추가되거나 B가 먼저 추가됨)에 따라 출력 결과가 달라질 수 있음.
- LIFO 구조를 활용하여 가장 최근에 추가된 노드를 우선적으로 탐색.
코드
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int vertex; // 연결된 노드 번호
struct Node* next; // 다음 노드를 가리키는 포인터
} Node;
Node** adjList; // 동적으로 생성할 포인터
int* visited; // 방문 여부를 동적 배열로 생성
int n; // 노드 개수
void addEdge(int src, int dest) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->vertex = dest;
newNode->next = adjList[src];
adjList[src] = newNode;
}
void DFS(int currentNode) {
visited[currentNode] = 1;
printf("%d ", currentNode);
Node* temp = adjList[currentNode];
while (temp != NULL) {
int nextVertex = temp->vertex;
if (!visited[nextVertex]) {
DFS(nextVertex);
}
temp = temp->next;
}
}
int main() {
int edges, src, dest;
printf("노드 개수를 입력하세요: ");
scanf("%d", &n);
// 동적 메모리 할당
adjList = (Node**)malloc(n * sizeof(Node*));
visited = (int*)malloc(n * sizeof(int));
for (int i = 0; i < n; i++) {
adjList[i] = NULL; // 초기화
visited[i] = 0; // 방문 여부 초기화
}
printf("간선 개수를 입력하세요: ");
scanf("%d", &edges);
for (int i = 0; i < edges; i++) {
printf("간선 (출발 노드, 도착 노드)을 입력하세요: ");
scanf("%d %d", &src, &dest);
addEdge(src, dest);
addEdge(dest, src); // 무방향 그래프
}
printf("DFS 탐색 결과: ");
DFS(0);
printf("\n");
// 동적 메모리 해제
for (int i = 0; i < n; i++) {
Node* temp = adjList[i];
while (temp != NULL) {
Node* toFree = temp;
temp = temp->next;
free(toFree); // 연결 리스트 해제
}
}
free(adjList);
free(visited);
return 0;
}입출력 예시
입력:
노드 개수와 간선 개수를 입력하세요: 5 4
간선 (출발 노드, 도착 노드)을 입력하세요: 0 1
간선 (출발 노드, 도착 노드)을 입력하세요: 0 2
간선 (출발 노드, 도착 노드)을 입력하세요: 1 3
간선 (출발 노드, 도착 노드)을 입력하세요: 1 4
출력:
DFS (스택) 탐색 결과: 0 1 4 3 2
이해가 어려웠던 점
Node** adjList 의 작동 방식
Node** adjList; // 동적으로 생성할 포인터
의문점 1) adjList는 왜 Node 포인터 리스트 형식이여야 했는가?
void addEdge(int src, int dest) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->vertex = dest;
newNode->next = adjList[src];
adjList[src] = newNode;
}
의문점 2) 노드를 생성하고 간선을 연결하는 과정에서 next라는 Node 구조체 변수에 adjList[src] 를 넣으면 무슨 작용이 일어나는가?
next의 역할은 간선을 연결해주는 역할인데 [0, 1, 0 0] 와 같은 리스트 전체를 반환하는게 아니라 adjList[src] 라는 Node의 특정 값을 저장하면 어떻게 간선으로서 작용할 수 있나?
의문점 해소 방법
: 코드을 작동시키면 adjList가 어떻게 동작하는지 과정을 보니까 이해가 되었습니다.
아래는 주어진 코드를 실행하면서 **adjList**가 어떻게 구성되고, 간선 정보가 추가될 때마다 어떻게 변하는지를 단계별로 설명한 것입니다.
초기 상태
- adjList 초기 상태:
- 모든 요소가 NULL로 초기화됩니다.
- 즉, 아직 어떤 노드도 연결되지 않았습니다.
adjList[0]: NULL adjList[1]: NULL adjList[2]: NULL adjList[3]: NULL adjList[4]: NULL
1단계: addEdge(0, 1) 실행
- 간선 0→10 \to 1이 추가됩니다.
- adjList[0]에 노드 1이 추가:
- 새로운 노드 생성: Node(vertex: 1, next: NULL)
- adjList[0]가 이 노드를 가리킴.
- adjList 상태:
adjList[0]: 1 → NULL
adjList[1]: NULL
adjList[2]: NULL
adjList[3]: NULL
adjList[4]: NULL- 무방향 그래프이므로 addEdge(1, 0) 실행:
- 간선 1→01 \to 0이 추가됩니다.
- 새로운 노드 생성: Node(vertex: 0, next: NULL)
- adjList[1]가 이 노드를 가리킴.
- adjList 상태:
adjList[0]: 1 → NULL
adjList[1]: 0 → NULL
adjList[2]: NULL
adjList[3]: NULL
adjList[4]: NULL2단계: addEdge(0, 2) 실행
- 간선 0→20 \to 2이 추가됩니다.
- adjList[0]에 노드 2가 추가:
- 새로운 노드 생성: Node(vertex: 2, next: 1 → NULL)
- adjList[0]가 새 노드를 가리킴.
- adjList 상태:
adjList[0]: 2 → 1 → NULL
adjList[1]: 0 → NULL
adjList[2]: NULL
adjList[3]: NULL
adjList[4]: NULL- 무방향 그래프이므로 addEdge(2, 0) 실행:
- 간선 2→02 \to 0이 추가됩니다.
- 새로운 노드 생성: Node(vertex: 0, next: NULL)
- adjList[2]가 이 노드를 가리킴.
- adjList 상태:
adjList[0]: 2 → 1 → NULL
adjList[1]: 0 → NULL
adjList[2]: 0 → NULL
adjList[3]: NULL
adjList[4]: NULL3단계: addEdge(1, 3) 실행
- 간선 1→31 \to 3이 추가됩니다.
- adjList[1]에 노드 3이 추가:
- 새로운 노드 생성: Node(vertex: 3, next: 0 → NULL)
- adjList[1]가 새 노드를 가리킴.
- adjList 상태:
adjList[0]: 2 → 1 → NULL
adjList[1]: 3 → 0 → NULL
adjList[2]: 0 → NULL
adjList[3]: NULL
adjList[4]: NULL- 무방향 그래프이므로 addEdge(3, 1) 실행:
- 간선 3→13 \to 1이 추가됩니다.
- 새로운 노드 생성: Node(vertex: 1, next: NULL)
- adjList[3]가 이 노드를 가리킴.
- adjList 상태:
adjList[0]: 2 → 1 → NULL
adjList[1]: 3 → 0 → NULL
adjList[2]: 0 → NULL
adjList[3]: 1 → NULL
adjList[4]: NULL4단계: addEdge(1, 4) 실행
- 간선 1→41 \to 4이 추가됩니다.
- adjList[1]에 노드 4가 추가:
- 새로운 노드 생성: Node(vertex: 4, next: 3 → 0 → NULL)
- adjList[1]가 새 노드를 가리킴.
- adjList 상태:
adjList[0]: 2 → 1 → NULL
adjList[1]: 4 → 3 → 0 → NULL
adjList[2]: 0 → NULL
adjList[3]: 1 → NULL
adjList[4]: NULL- 무방향 그래프이므로 addEdge(4, 1) 실행:
- 간선 4→14 \to 1이 추가됩니다.
- 새로운 노드 생성: Node(vertex: 1, next: NULL)
- adjList[4]가 이 노드를 가리킴.
- 최종 adjList 상태:
adjList[0]: 2 → 1 → NULL
adjList[1]: 4 → 3 → 0 → NULL
adjList[2]: 0 → NULL
adjList[3]: 1 → NULL
adjList[4]: 1 → NULL최종 상태
- 노드와 연결된 인접 노드들:
0: 2 → 1 1: 4 → 3 → 0 2: 0 3: 1 4: 1
DFS 과정에서 adjList의 역할
- adjList는 변하지 않고 고정됩니다.
- 탐색 중에 현재 노드에서 adjList를 참조하여 인접 노드들을 스택에 추가합니다.
- 예를 들어, DFS 탐색이 노드 0에서 시작할 경우:
- adjList[0]: 2 → 1 → NULL을 탐색하여 노드 2와 1을 스택에 추가합니다.
두 방식의 차이점
- 재귀 기반 DFS:
- 함수 호출 스택을 사용하여 노드 간 이동 및 백트래킹을 처리.
- 코드가 간결하고 이해하기 쉬움.
- 큰 그래프나 깊은 탐색 시 스택 오버플로우 가능.
- 스택 기반 DFS:
- 명시적인 스택 자료구조를 사용하여 백트래킹 처리.
- 스택 깊이에 제한이 없어 더 안정적으로 동작.
- 스택 관리 코드로 인해 재귀 방식보다 구현이 약간 복잡.
'Computer Science > 자료구조 & 알고리즘' 카테고리의 다른 글
| [자료구조 & 알고리즘] BFS 알고리즘 구현 시 자료구조[배열/리스트]를 선택하는 방법과 이유(feat. 밀집그래프, 희소그래프) (1) | 2024.12.25 |
|---|---|
| [자료구조 & 알고리즘] 그래프 + BFS (0) | 2024.12.22 |
| [자료구조 & 알고리즘] 정렬 알고리즘 총 정리 (0) | 2024.12.18 |
| [자료구조 & 알고리즘] 탐색 알고리즘 총 정리 (feat. 이진탐색, DFS, BFS) (2) | 2024.12.17 |
| [자료구조 & 알고리즘] 자료구조 개념 총정리 (향후 내용추가) (2) | 2024.12.16 |



